A while ago I wrote about learning from failure. This is a story of failure; Hardware failure, failure of design and failure of my self (The systems administrator) to not correct the issues earlier. It's hard to write about, but I believe that stories of failure can teach us just as much, if not more, than stories of successes.
I inherited a system where a number of VMs were running on top of two Hyper-V hosts, with a single NAS hosting a .VHD file that was shared as an iSCSI target for the storage of the .VHDs that were the VM disks.
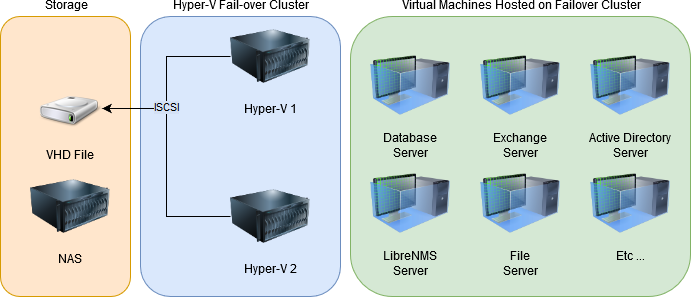
Now, this design is not great for a number of reasons that will become apparent throughout this post, but a few that should immediately jump out is that the one NAS provides a single point of failure, and that using a .VHD file as the iSCSI target will not provide great performance, it would be better to use the disk directly.
So the first failure is that I never upgraded this setup to something more robust, I had ample time and the budget was available but I took an attitude of "If it's not broken, don't fix it". That is the wrong attitude to have, sure no one was complaining about the performance and it was running ok so but I could have fixed all of these issues before they even started, and I did not.
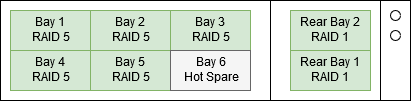
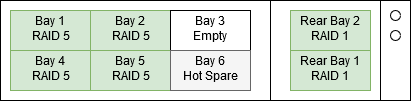
2017-03-01 03:00 Drive in Bay 1 dies
I'm blissfully asleep, maybe I rolled over and scratch my ear.

2017-03-01 03:00 Servers blue screen
In theory, because the NAS has a RAID5 + Hot Spare, everything should keep ticking along even after one drive dies. However the server froze up for just long enough the iSCSI connection timed out and the servers could no longer read and write to their disks, so all the VMs crashed.
Critically this includes the Exchange server, so the email alert about a failed disk that the HP ILO should have sent goes nowhere.
2017-03-01 08:30 I get to work, and reboot servers
I get to work and am immediately told that nothing is working, so I remote into the Hyper-V servers and reboot all the VMs. They come back up ok and I spend a bit of time trying to work out why they failed but somehow I completely miss the fact that one of the disks in the NAS has died. I think I assumed it was related to a bad Windows Update for Hyper-V or something.
2017-03-01 21:00 Servers blue screen again
The servers bluescreen again, due to read/write timeout. Only this time the nightly backups fail to run as well.
2017-03-02 08:30 I replace drive in bay 1
I get to work and for a second day, all the servers are down. I reboot them and then I finally I see that the drive in bay 1 of the NAS is dead. We don't have a cold spare on site so I go down to the local computer shop and buy a new drive.
Fortunately, It's a RAID 5 with Hot Spare array so it has already rebuilt into the hot spare.
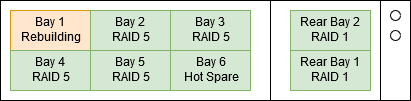
2017-03-02 09:45 Rebuilding at 12% Hot spare dies. Rebuilding starts again at 0%.
I'm sitting at my desk watching the array rebuild onto the drive in Bay 1 and then suddenly... The hot spare dies. I suspect that the hot spare had actually been dodgy for a while, but because we were using RAID 5 with a Hot Spare rather than RAID 6 the disk wasn't in use and so we never got alerted that it was bad.

Fortunately, we still have enough data on the 4 remaining disks to rebuild the array but now instead of a straight copy from the hot spare to the new disk, it's got to actually calculate the parity bits all over again. So the rebuild is not running much slower.
I replace the hot spare with a new blank drive.
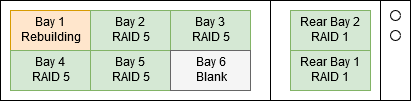
2017-03-02 20:00 Rebuilding at 80%. Drive in bay 3 marked "predicted failure".
I spend the rest of the day not being very productive and checking the rebuild progress every 10 minutes or so. Then at about 20:00 when I log in to have a look, the drive in bay 3 is marked as predicted failure.
Last night's backups failed, tonight's backups have not run yet because I've disabled them while the array is rebuilding. But if Disk 3 dies before Disk 1 is online we won't have enough disks left to rebuild the array.

2017-03-02 21:30 Rebuilding hits 100%
The last few minutes were nail-bitingly intense. But finally, the array has rebuilt. I start the backups and go to bed, unfortunately, the backups fail again.

2017-03-03 10:00 A consultant comes in
Where I work I'm essentially a one-person IT team, I've got a colleague who is very technical and good to bounce ideas off, but they are not in a full time IT role. But we have an external IT consultant that we use if I need help or to cover for me while I'm away on leave, so we called the consultant in for a bit of extra support.
2017-03-03 12:00 We remove the drive in bay 3. NAS crashes. We replace the drive in bay 3.
After some discussion, we decide that the next step is to remove the drive in bay 3. Rather than waiting until the end of the day, or for the predicted failure, let's just pull it and get the array rebuilding onto the hot spare as soon as possible.
I've pulled drives out of servers with hardware RAID before and they have been fine. I'd just recently pulled drives out of this NAS before and had no issues. But as soon as I pulled the drive out from bay 3, the NAS bluescreened and wouldn't reboot despite the fact that the OS was on a separate RAID array.
Naturally, all the VMs bluescreened as well and people were displeased that all the systems had stopped working in the middle of the day. I replaced the faulty drive back into bay 3 and then NAS booted.
We decided not to touch the NAS again during working hours.
2017-03-03 17:45 I start manually copying VHD files off to USB drive.
At this point, it's a Friday afternoon and I don't have a successful backup since Tuesday night. Veeam is failing, so I start copying the VHD files (for the VMs) onto a USB hard drive.
2017-03-04 21:00 Copying the File Server D drive is still failing. I shut down the NAS and put a new drive in bay 3.
All the servers are backed up except the File Server D drive which won't copy, but I'm running out of time. So I shut down the NAS and replace the drive in bay 3 with a blank one and the server boot. I rebuild the array offline which is quicker than while it's running but still slow.

2017-03-05 08:00 Array is rebuilt, File Server D drive is still failing
The array is back up and looking healthy. But Veeam is still failing to back up the fileserver D drive.
2017-03-05 19:00 chkdsk /f File Server D overnight
I had to shut all the servers down, unmount the iSCSI drive and run chkdsk /f, it runs over the whole night and finally finishes only to report no errors on NAS. But the Fileserver D drive backups are still failing.
2017-03-06 07:00 chkdsk /R on the NAS
Luckily Monday was a public holiday and I could continue to work leave the VMs shutdown and work on the NAS without causing interruptions to staff, so first thing in the morning I start chkdsk /r. I wrote about Veeam backup errors after NAS hard drive failure.
2017-03-06 20:00 chkdsk finishes. I boot all servers and start a backup.
Finally chkdsk finishes and reports that it's fixed a number of issues. I still don't know for sure that I've fixed the issue with the backups but I'm feeling a little better.
2017-03-07 06:00 File server D finishes the backup.
Finally, I can breathe a huge sigh of relief after a full week of outages and issues everything seems to be running normally again.
Over the next few months
Over the new few months, I worked to decommission this setup and move to a more robust design, including shutting down our VMs and migrating many of our services to the cloud. This system is now thankfully no longer in use and I can sleep easier knowing I will never again need to go through that ordeal.
Also importantly, I've learned the hard way about the importance of proactive maintenance and not having a single point of failure. Fortunately, in this case, there was no data loss, but it came far too close for comfort.
